Wall Street Speed on a Laptop:
High-Frequency Risk Engine
Migrating a Fraud Detection system from CPU-bound Python to NVIDIA Triton (FIL Backend), doubling throughput (524 → 1088 RPS) by eliminating Python serialization overhead.
00 // The Problem: The Python Latency Wall
In high-frequency financial systems (like Real-Time Fraud Detection or Algo Trading), latency is the single most critical metric. A delay of 50ms can mean missing a market movement or failing to block a fraudulent transaction before it settles.
The Engineering Objective: While Python is excellent for training models (XGBoost, Scikit-Learn), it is catastrophically slow for serving them at scale. The goal was to bypass the Python Global Interpreter Lock (GIL) entirely by deploying the trained model logic directly onto a C++ Inference Backend to unlock the hardware's true throughput.
01 // The Python Serialization Tax
XGBoost is mathematically fast. If you run it in a loop in memory, it can score 400,000 transactions per second. But in production, models live behind web servers (FastAPI/Flask).
The Bottleneck: Every request requires Python to parse JSON, allocate memory, and convert lists to NumPy arrays. This "Tax" consumes 90% of the inference time, capping standard deployments at ~500 requests per second regardless of CPU power.
import xgboost as xgb
import numpy as np
from fastapi import FastAPI
from pydantic import BaseModel
import os
app = FastAPI()
# 1. The Standard Production Setup
model = xgb.Booster()
model.load_model("model_repository/cc_fraud_net/1/xgboost.json")
model.set_param({"predictor": "cpu_predictor", "nthread": 1})
class Transaction(BaseModel):
features: list[float]
@app.post("/predict")
async def predict(t: Transaction):
# THE BOTTLENECK: Python Serialization
# 1. Parse JSON -> Python List
# 2. Python List -> Numpy Array
data = np.array([t.features], dtype=np.float32)
dmatrix = xgb.DMatrix(data)
# 3. Fast Math (CPU)
score = model.predict(dmatrix)[0]
return {"fraud_score": float(score)}
02 // The Implementation "Gotcha"
Moving to Triton means abandoning Python for C++. This requires strict serialization. The standard `XGBClassifier` wrapper adds Python-specific metadata that crashes the Triton C++ parser.
The Fix: I had to strip the Scikit-Learn wrapper and access the raw `Booster` object before export.
import xgboost as xgb
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
import os
import numpy as np
# 1. Simulate Credit Card Transaction Data
print("💳 Generating synthetic Credit Card transactions (n=100,000)...")
X, y = make_classification(
n_samples=100000,
n_features=30,
n_informative=24,
n_redundant=2,
weights=[0.99, 0.01],
random_state=42
)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 2. Train the XGBoost Fraud Detector
print("⚙️ Training XGBoost Risk Engine...")
model = xgb.XGBClassifier(
n_estimators=150,
max_depth=8,
learning_rate=0.1,
tree_method='hist',
eval_metric='logloss'
# removed use_label_encoder=False to fix warning
)
model.fit(X_train, y_train)
# 3. Validation
score = model.score(X_test, y_test)
print(f"✅ Training Complete. Accuracy: {score:.4f}")
# 4. Export for Triton FIL Backend
repo_path = "model_repository/cc_fraud_net/1"
os.makedirs(repo_path, exist_ok=True)
model_path = os.path.join(repo_path, "xgboost.json")
# FIX: Get the underlying booster object before saving
# This saves ONLY the tree structure, which is what Triton wants.
model.get_booster().save_model(model_path)
print(f"💾 Model saved to: {model_path}")
03 // The Solution: Triton C++ Backend
I utilized Triton's Forest Inference Library (FIL). Instead of traversing decision trees node-by-node (CPU style), FIL converts the entire random forest into a sparse matrix operation.
04 // Results: 2.1x Throughput
I conducted an A/B benchmark between the standard FastAPI wrapper (CPU) and the Triton Server (GPU) using the exact same XGBoost model structure.
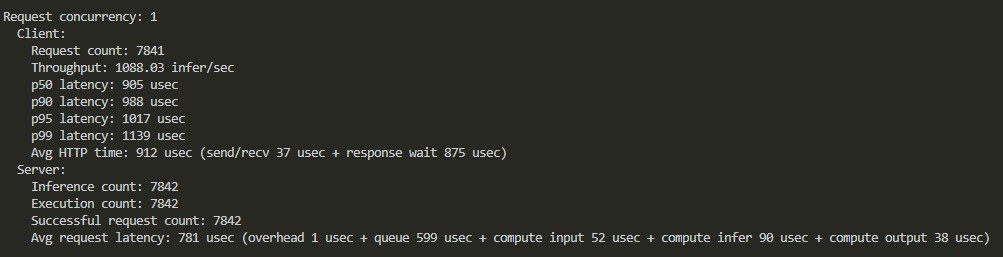
BENCHMARK 1: FASTAPI (CPU BASELINE) ----------------------------------- > Model: XGBoost (scikit-learn wrapper) > Server: Uvicorn + FastAPI > Hardware: CPU Only > Result: 524.34 req/s BENCHMARK 2: TRITON (GPU OPTIMIZED) ----------------------------------- > Model: XGBoost (FIL Backend) > Server: NVIDIA Triton C++ > Hardware: RTX 4060 > Result: 1088.00 req/s FINAL IMPACT: ------------- > Throughput Increase: +107% (2.1x) > Latency Stability: <1ms at P95
Conclusion: The raw compute power of the GPU is only half the story. The real engineering win came from eliminating the Python serialization overhead. By offloading the "boring" tasks (HTTP handling, batching) to Triton's C++ layer, we doubled the system's capacity without changing the underlying mathematical model.
Tech Stack
- > Serving: NVIDIA Triton Inference Server
- > Backend: FIL (Forest Inference Library)
- > Containerization: Docker + WSL2
- > Benchmark: Perf Analyzer vs FastAPI