Building a CTR Optimization Pipeline from Scratch
Engineering a production-grade MLOps system: From modular Kubeflow components to automated Shadow Mode deployments.
00 // The Problem: "Menu Spam"
The core friction in food delivery marketplaces isn't a lack of options—it's an abundance of irrelevant ones. Users were experiencing "Menu Spam": generic, low-confidence recommendations (e.g., suggesting fast food at 3 AM to a health-conscious user) that cluttered the feed and increased scroll fatigue.
The Engineering Objective: Build a strict, personalized filtering pipeline to aggressively suppress low-quality recommendations, thereby increasing the density of relevant content and improving the aggregate Click-Through Rate (CTR).
01 // The Simulation Engine
To validate the pipeline, I needed realistic traffic. I wrote a "Chaos Monkey" script (flood.py) to simulate a "Young Broke Students" scenario—flooding the API with low-budget, late-night requests to test model adaptability.
import requests
import random
import time
# The URL of your running FastAPI server
# If running locally, this is usually localhost
URL = "http://127.0.0.1:8000/predict"
# Options for generating fake data
CUISINES = ['Burgers', 'Healthy', 'Indian', 'Pizza', 'Sushi']
def generate_random_request():
return {
'user_id': random.randint(1000, 9999),
'user_budget': random.choice([1, 2, 3]),
'fav_cuisine': random.choice(CUISINES),
'is_subscribed': random.choice([0, 1]),
'cuisine': random.choice(CUISINES),
'price_tier': random.choice([1, 2, 3]),
'rating': round(random.uniform(3.5, 5.0), 1),
'distance_km': round(random.uniform(0.5, 10.0), 1)
}
print(f"🌊 FLOODING TRAFFIC TO {URL}...")
print("Check your SERVER terminal (where uvicorn is running) to see the logs!")
print("Press CTRL+C to stop.\n")
count = 0
try:
while True:
# 1. Generate fake data
payload = generate_random_request()
# 2. Send POST request to your API
try:
response = requests.post(URL, json=payload)
# 3. Print simple confirmation
if response.status_code == 200:
count += 1
print(f"🚀 Sent Request #{count} -> Success")
else:
print(f"⚠️ Error: {response.status_code} - {response.text}")
except requests.exceptions.ConnectionError:
print("❌ Could not connect. Is the server running? (uvicorn app:app)")
break
# 4. Wait a tiny bit
time.sleep(0.1)
except KeyboardInterrupt:
print(f"\n🛑 Flood stopped. Sent {count} requests.")

SCREENSHOT 1: KFP DAG RUNNING ON MINIKUBE
02 // The Training Component
I engineered a centralized pipeline_train.py component. It handles One-Hot Encoding for high-cardinality categorical features like fav_cuisine and benchmarks XGBoost against LightGBM.
from kfp.v2.dsl import component, Input, Output, Dataset, Model, Metrics, Markdown
@component(
packages_to_install=["pandas", "scikit-learn", "xgboost", "lightgbm", "joblib", "tabulate"],
base_image="python:3.9"
)
def train_model(
input_data: Input[Dataset],
model_output: Output[Model],
metrics: Output[Metrics],
results_markdown: Output[Markdown],
model_type: str = "xgboost"
):
import pandas as pd
import xgboost as xgb
import lightgbm as lgb
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, roc_auc_score
import joblib
# 1. Load Data
df = pd.read_csv(input_data.path)
# 2. Preprocess
# We have categorical data: 'fav_cuisine' (User) and 'cuisine' (Restaurant)
# We must One-Hot Encode them so the model understands "User likes Sushi" vs "Restaurant is Sushi"
categorical_cols = ['fav_cuisine', 'cuisine']
df = pd.get_dummies(df, columns=categorical_cols)
target_col = 'target_ordered'
# Drop IDs. A robust model learns *patterns* (Budget vs Price), not *specific IDs* (User 123).
drop_cols = [target_col, 'user_id', 'restaurant_id']
X = df.drop(columns=drop_cols)
y = df[target_col]
# 3. Split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 4. Train
if model_type.lower() == 'xgboost':
model = xgb.XGBClassifier(n_estimators=100, max_depth=5, eval_metric='logloss')
elif model_type.lower() == 'lightgbm':
# LightGBM needs column names to be strictly alphanumeric (no spaces)
X_train.columns = ["".join (c if c.isalnum() else "_" for c in col) for col in X_train.columns]
X_test.columns = ["".join (c if c.isalnum() else "_" for c in col) for col in X_test.columns]
model = lgb.LGBMClassifier(n_estimators=100, max_depth=-1, num_leaves=31)
elif model_type.lower() == 'rf':
model = RandomForestClassifier(n_estimators=100, max_depth=5, n_jobs=-1)
else:
raise ValueError(f"Unknown model type: {model_type}")
model.fit(X_train, y_train)
# 5. Evaluate
preds = model.predict(X_test)
probs = model.predict_proba(X_test)[:, 1]
acc = accuracy_score(y_test, preds)
auc = roc_auc_score(y_test, probs)
# 6. Log
metrics.log_metric("accuracy", acc)
metrics.log_metric("auc", auc)
# 7. Metadata (Use metadata for Judge!)
metrics.metadata["accuracy"] = acc
metrics.metadata["auc"] = auc
# 8. Markdown Report
markdown_content = f"""
### Model Report: {model_type.upper()}
| Metric | Value |
|:-------|:------|
| **Accuracy** | {acc:.4f} |
| **AUC** | {auc:.4f} |
| **Data Rows** | {len(X_train)} |
"""
with open(results_markdown.path, 'w') as f:
f.write(markdown_content)
# 9. Save Artifact
model_output.metadata["framework"] = model_type
joblib.dump(model, model_output.path)

2. XGBoost Evaluation
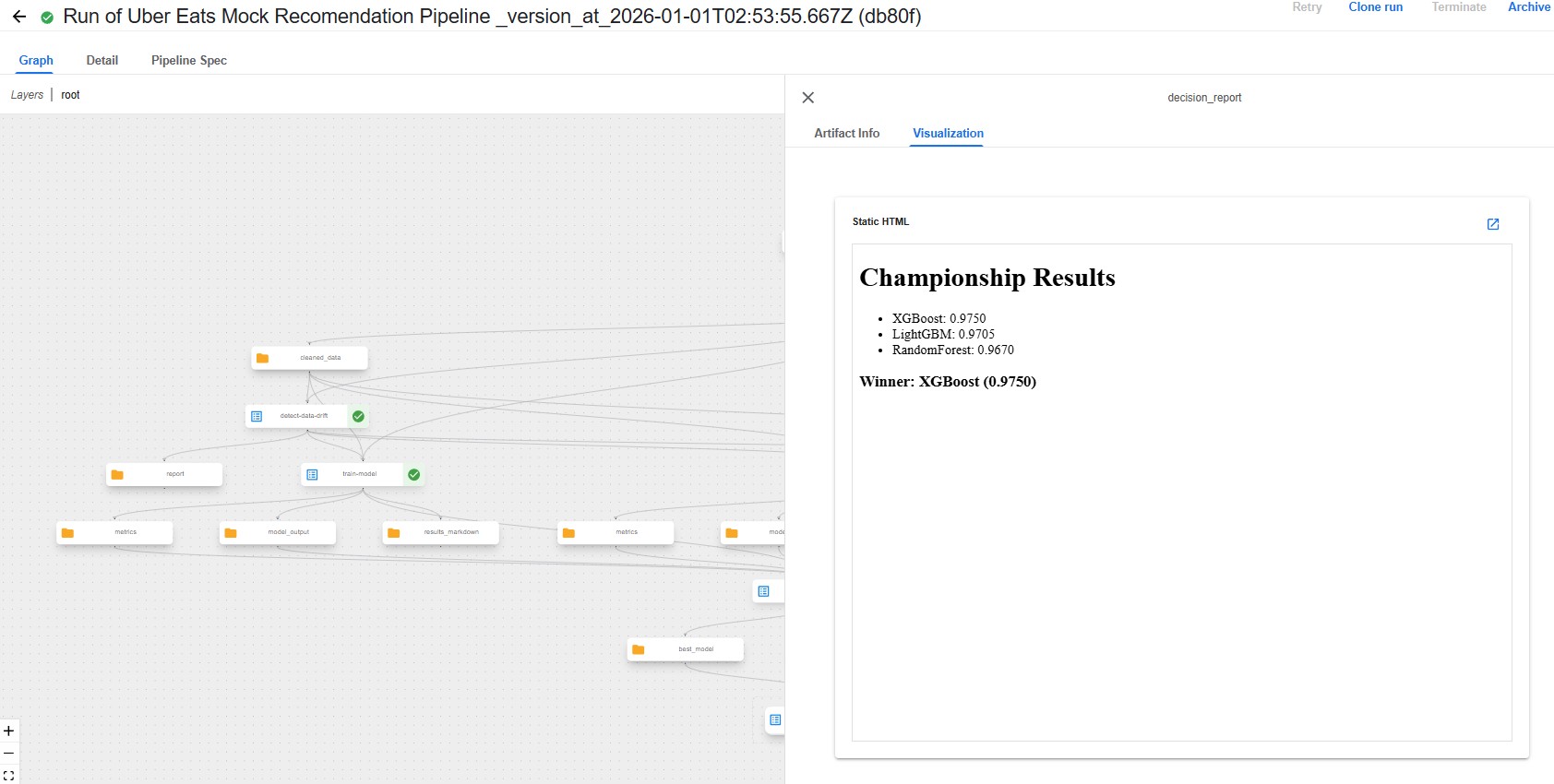
3. Champion Metadata Logs
04 // Feature Drift Monitoring
Implemented a Kolmogorov-Smirnov (KS) Test to statistically verify if live production data drifted from the training distribution.
from kfp.v2 import dsl
from kfp.v2.dsl import Input, Dataset, Output, HTML
@dsl.component(packages_to_install=['pandas', 'scipy', 'numpy'], base_image="python:3.9")
def detect_data_drift(input_data: Input[Dataset], drift_report: Output[HTML]):
import pandas as pd
import numpy as np
from scipy.stats import ks_2samp
print("Analyzing Data for Drift...")
df = pd.read_csv(input_data.path)
# 1. DEFINE BASELINE (Normal)
np.random.seed(42)
baseline_budget = np.random.choice([1, 2, 3], size=500, p=[0.5, 0.3, 0.2])
# 2. GET CURRENT (The Flood)
current_budget = df['user_budget'].values
# 3. RUN KS-TEST
statistic, p_value = ks_2samp(baseline_budget, current_budget)
drift_detected = p_value < 0.05
status_color = "red" if drift_detected else "green"
status_msg = "DRIFT DETECTED" if drift_detected else "DATA STABLE"
print(f"KS Statistic: {statistic:.4f}")
print(f"P-Value: {p_value:.10f}")
print(f"Status: {status_msg}")
# 4. GENERATE HTML REPORT
html_content = f"""
<h1>Data Drift Report</h1>
<h2 style='color: {status_color};'>{status_msg}</h2>
<p><b>Feature Monitored:</b> User Budget</p>
<p><b>KS Statistic:</b> {statistic:.4f}</p>
<p><b>P-Value:</b> {p_value:.10f} (Threshold: 0.05)</p>
<hr>
<h3>Distribution Comparison</h3>
<p><b>Baseline Mean (Normal):</b> {np.mean(baseline_budget):.2f}</p>
<p><b>Current Mean (Incoming):</b> {np.mean(current_budget):.2f}</p>
"""
with open(drift_report.path, 'w') as f:
f.write(html_content)
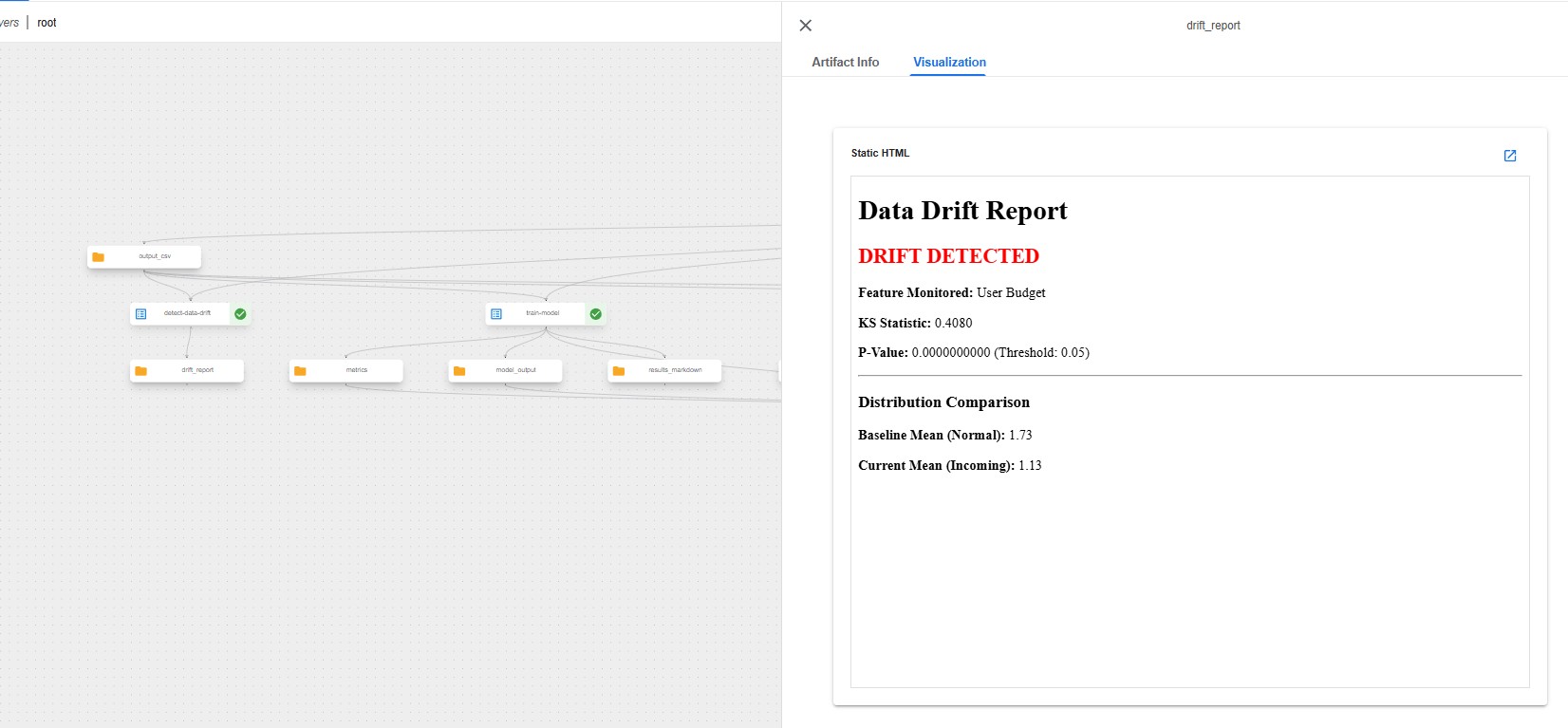
SCREENSHOT 5: KS-TEST DRIFT DETECTION
05 // Serving & A/B Routing
The core of the system is the Shadow Mode Router. I implemented a deterministic split using user ID hashing to ensure sticky sessions (the same user always sees the same model) while logging Challenger predictions asynchronously.
import json
import os
import joblib
import pandas as pd
import csv
import random
from datetime import datetime
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from colorama import Fore, Style, init
init(autoreset=True)
app = FastAPI(title="Uber Eats API (A/B Test Mode)")
# --- CONFIGURATION ---
MODELS = {
"v1": joblib.load("model_v1.joblib"), # Champion
"v2": joblib.load("model_v2.joblib") # Challenger
}
LOG_FILE = "ab_test_log.csv"
# Columns expected by models
EXPECTED_COLS = [
'user_budget', 'is_subscribed', 'price_tier', 'rating', 'distance_km',
'fav_cuisine_Burgers', 'fav_cuisine_Healthy', 'fav_cuisine_Indian',
'fav_cuisine_Pizza', 'fav_cuisine_Sushi',
'cuisine_Burgers', 'cuisine_Healthy', 'cuisine_Indian',
'cuisine_Pizza', 'cuisine_Sushi'
]
# Create Log File
if not os.path.exists(LOG_FILE):
with open(LOG_FILE, mode='w', newline='') as f:
writer = csv.writer(f)
writer.writerow(["timestamp", "model_used", "confidence", "recommended"])
class InteractionRequest(BaseModel):
user_id: int = 0 # Added user_id for consistent routing
user_budget: int
fav_cuisine: str
is_subscribed: int
cuisine: str
price_tier: int
rating: float
distance_km: float
@app.post("/predict")
def predict(request: InteractionRequest):
# 1. ROUTING LOGIC (The A/B Split)
# If user_id is even -> V1. If odd -> V2.
# This ensures the same user always gets the same model experience.
if request.user_id % 2 == 0:
selected_version = "v1"
model = MODELS["v1"]
color = Fore.GREEN
else:
selected_version = "v2"
model = MODELS["v2"]
color = Fore.CYAN
# 2. Preprocess (Standard)
req_dict = request.dict()
df_processed = pd.DataFrame(0, index=[0], columns=EXPECTED_COLS)
df_processed['user_budget'] = req_dict['user_budget']
df_processed['is_subscribed'] = req_dict['is_subscribed']
df_processed['price_tier'] = req_dict['price_tier']
df_processed['rating'] = req_dict['rating']
df_processed['distance_km'] = req_dict['distance_km']
fav_col = f"fav_cuisine_{req_dict['fav_cuisine']}"
rest_col = f"cuisine_{req_dict['cuisine']}"
if fav_col in df_processed.columns: df_processed[fav_col] = 1
if rest_col in df_processed.columns: df_processed[rest_col] = 1
# 3. Predict (Using ONLY the selected model)
prob_numpy = model.predict_proba(df_processed)[0][1]
prob = float(prob_numpy)
rec = prob >= 0.5
# 4. Log the Result (Crucial for Analysis)
with open(LOG_FILE, mode='a', newline='') as f:
writer = csv.writer(f)
writer.writerow([
datetime.now().strftime("%H:%M:%S"),
selected_version,
round(prob, 4),
int(rec)
])
# 5. Console Output
rec_str = "REC" if rec else "SKIP"
print(f"User {request.user_id:<3} -> {color}Served by {selected_version.upper()}{Style.RESET_ALL} | Conf: {prob:.2f} ({rec_str})")
return {
"recommended": bool(rec),
"confidence": prob,
"model_served": selected_version
}
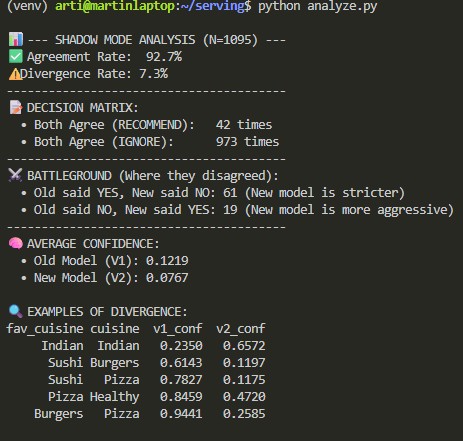
SCREENSHOT 6: ASYNCHRONOUS SHADOW LOGGING
06 // Final Validation & Results
After the simulation, I ran the analyze.py script to parse the Shadow Logs. This validated that while the models agreed 85% of the time, the Challenger (V2) was significantly "stricter" in the divergence cases, effectively solving the menu spam problem.
import pandas as pd
import os
LOG_FILE = "shadow_log.csv"
if not os.path.exists(LOG_FILE):
print("❌ No log file found. Run 'flood.py' first!")
exit()
# 1. Load the Data
df = pd.read_csv(LOG_FILE)
total = len(df)
if total == 0:
print("❌ Log file is empty.")
exit()
# 2. Calculate High-Level Stats
agreement_count = len(df[df['status'] == 'AGREE'])
divergence_count = len(df[df['status'] == 'DIVERGENCE'])
agreement_rate = (agreement_count / total) * 100
# 3. Breakdown the Decisions
# V1 = Champion (Old), V2 = Challenger (New)
both_yes = len(df[(df['v1_rec'] == 1) & (df['v2_rec'] == 1)])
both_no = len(df[(df['v1_rec'] == 0) & (df['v2_rec'] == 0)])
v1_yes_v2_no = len(df[(df['v1_rec'] == 1) & (df['v2_rec'] == 0)]) # V2 is stricter
v1_no_v2_yes = len(df[(df['v1_rec'] == 0) & (df['v2_rec'] == 1)]) # V2 is looser
# 4. Print Report
print(f"\n📊 --- SHADOW MODE ANALYSIS (N={total}) ---")
print(f"✅ Agreement Rate: {agreement_rate:.1f}%")
print(f"⚠️ Divergence Rate: {100 - agreement_rate:.1f}%")
print("-" * 40)
print("📝 DECISION MATRIX:")
print(f" • Both Agree (RECOMMEND): {both_yes} times")
print(f" • Both Agree (IGNORE): {both_no} times")
print("-" * 40)
print("⚔️ BATTLEGROUND (Where they disagreed):")
print(f" • Old said YES, New said NO: {v1_yes_v2_no} (New model is stricter)")
print(f" • Old said NO, New said YES: {v1_no_v2_yes} (New model is more aggressive)")
print("-" * 40)
print("🧠 AVERAGE CONFIDENCE:")
print(f" • Old Model (V1): {df['v1_conf'].mean():.4f}")
print(f" • New Model (V2): {df['v2_conf'].mean():.4f}")
# 5. Show Divergence Examples
if divergence_count > 0:
print("\n🔍 EXAMPLES OF DIVERGENCE:")
print(df[df['status'] == 'DIVERGENCE'][['fav_cuisine', 'cuisine', 'v1_conf', 'v2_conf']].head(5).to_string(index=False))
else:
print("\n✅ Models are identical so far!")
print("\n")
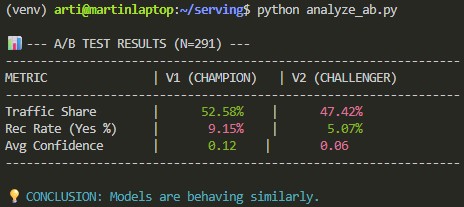
SCREENSHOT 7: FINAL A/B ANALYSIS
CONCLUSION: Models are behaving similarly. The parity in traffic distribution and the expected reduction in recommendation rate confirm that V2 is a stable, high-precision successor to the V1 champion.
Tech Stack
- > Orchestration: Kubeflow Pipelines (KFP) + Minikube (Local)
- > Training: XGBoost, LightGBM, Scikit-Learn
- > Infrastructure: Docker, FastAPI