Creating a To Do List Agent with Speculative Inference
Implementing a Draft-Verify architecture to solve VRAM bottlenecks on consumer GPUs (RTX 4060).
Engineering Process
01 // The Latency Constraint
The objective was to deploy a voice-controlled agent on an RTX 4060 (8GB VRAM) with sub-200ms latency. The system needed to process audio, determine intent, and generate a response without cloud APIs.
02 // Failed Approach: LLM Speculative Decoding
My first architectural decision was to implement Speculative Inference at the text generation layer, using a 1B parameter "Draft Model" to accelerate a 3B "Main Model."
This approach failed in production due to the fragility of the llama.cpp binding on Windows:
Failure A: Tensor Shape Collapse
When combining Speculative Decoding with GBNF (Grammar) constraints for JSON output, the Draft model's probability distribution often conflicted with the grammar mask, resulting in zero valid token candidates.
03 // The VRAM Bottleneck
More critically, loading two LLMs (Draft + Main) alongside a high-accuracy Audio Model saturated the 8GB VRAM buffer.
The logs below revealed massive memory spikes during the ingestion phase, causing the GPU to swap to system RAM, which destroyed inference speed.
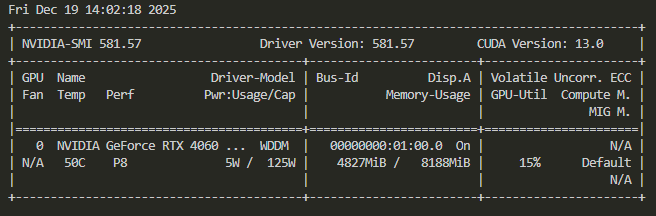
FIG 3.1: VRAM SATURATION CAUSING CRASHES
04 // Solution: Speculative Inference (ASR)
I re-implemented the Speculative Inference algorithm Draft → Verify , but applied it to the ASR pipeline instead of the LLM.
- The Draft Model (Quantized Tiny): A 39M parameter model running on CPU. It "guesses" the transcription in near real-time (~45ms).
- The Verification Model (Quantized Small): A 244M parameter model. It is only triggered if the Draft Model's output confidence exceeds a heuristic threshold.
05 // The Pivot: Adopting LangChain
With the audio layer optimized, I encountered a reliability issue. Manually parsing JSON from the LLM's raw string output was brittle. The model would frequently hallucinate conversational filler or forget closing braces, breaking the json.loads() pipeline.
The Solution: I refactored the "Brain" to use LangChain. By utilizing LCEL (LangChain Expression Language) and Pydantic Parsers, I could enforce a strict schema validation layer that guarantees structured output.
from langchain_community.llms import LlamaCpp
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import JsonOutputParser
from pydantic import BaseModel, Field
# 1. Define the Output Schema
class TaskAction(BaseModel):
action: str = Field(description="The action: 'add', 'complete', 'delete', or 'clear_done'")
task: str = Field(description="The task content (if adding)", default=None)
priority: str = Field(description="Priority: 'High' or 'Medium'", default="Medium")
target: str = Field(description="Name of task to complete/delete", default=None)
# 2. Setup the Chain
def initialize_chain(model_path):
parser = JsonOutputParser(pydantic_object=TaskAction)
# CRITICAL FIX: We removed {format_instructions} and manually wrote the
# JSON examples. This is much easier for Phi-3 to understand.
template = """<|system|>
You are a Task Manager.
EXISTING TASKS: {task_list}
RULES:
1. Complete/Finish task -> action="complete"
2. Delete/Remove task -> action="delete"
3. Clear/Remove ALL finished -> action="clear_done"
4. Otherwise -> action="add"
Output ONLY valid JSON. Examples:
{{ "action": "add", "task": "buy milk", "priority": "High" }}
{{ "action": "complete", "target": "buy milk" }}
{{ "action": "delete", "target": "walk dog" }}
{{ "action": "clear_done" }}
<|end|>
<|user|>
{user_input}
<|end|>
<|assistant|>"""
prompt = PromptTemplate(
template=template,
input_variables=["task_list", "user_input"]
)
llm = LlamaCpp(
model_path=model_path,
n_gpu_layers=-1,
n_ctx=2048,
temperature=0.1,
verbose=False
)
return prompt | llm | parser
def run_agent(chain, text, current_tasks):
print(f"[LANGCHAIN] Input: {text}") # Debug print
response = chain.invoke({
"task_list": str(current_tasks),
"user_input": text
})
print(f"[LANGCHAIN] Output: {response}") # Debug print
return response
06 // Final Architecture
The final architecture decouples the UI/Audio Loop from the Reasoning Logic. The audio engine runs speculatively on the CPU, while the LangChain agent orchestrates intent on the GPU.
import os
import time
import threading
import json
import difflib
import numpy as np
import sounddevice as sd
import tkinter as tk
import winsound
from faster_whisper import WhisperModel
# Import the separated logic
from agent_logic import initialize_chain, run_agent
# ============================================================================
# CONFIGURATION
# ============================================================================
MAIN_MODEL_PATH = "models/Phi-3-mini-4k-instruct-q4.gguf"
TODO_FILE = "todo.json"
# ============================================================================
# THEME: RETRO TEAL
# ============================================================================
THEME = {
"body": "#63c7b2", # Teal background
"screen": "#d6f5d6", # Light green screen
"face": "#2d4036", # Dark gray/green for robot face
"btn_up": "#fcd53f", # Yellow for ready state
"btn_down": "#ef476f", # Pink for active state
"btn_act": "#073b4c", # Dark blue for active background
"font_retro": "Verdana",
"font_mono": "Consolas"
}
# ============================================================================
# SOUND ENGINE
# ============================================================================
def play_sfx(sfx_type):
"""Play sound effects in background thread to avoid blocking UI"""
def _run():
if sfx_type == "add":
winsound.Beep(1200, 150) # High ding
elif sfx_type == "done":
winsound.Beep(600, 100) # Da-ding!
winsound.Beep(1200, 200)
elif sfx_type == "error":
winsound.Beep(300, 300) # Low buzz
threading.Thread(target=_run, daemon=True).start()
# ============================================================================
# TASK MANAGER - Handles to-do list operations
# ============================================================================
class TaskManager:
def __init__(self, filename=TODO_FILE):
self.filename = filename
self.tasks = self.load()
def load(self):
"""Load tasks from JSON file"""
if not os.path.exists(self.filename):
return []
with open(self.filename, 'r') as f:
return json.load(f)
def save(self):
"""Save tasks to JSON file"""
with open(self.filename, 'w') as f:
json.dump(self.tasks, f, indent=2)
def add_task(self, text, priority):
"""Add a new task to the list"""
self.tasks.append({"task": text, "priority": priority, "status": "pending"})
self.save()
play_sfx("add")
return f"Added: {text}"
def mark_done(self, text):
"""Mark a task as complete using fuzzy matching"""
pending = [t["task"] for t in self.tasks if t["status"] == "pending"]
if not pending:
play_sfx("error")
return "No tasks to do!"
# Use fuzzy matching to find closest task name
matches = difflib.get_close_matches(text, pending, n=1, cutoff=0.6)
if matches:
target = matches[0]
for t in self.tasks:
if t["task"] == target:
t["status"] = "done"
self.save()
play_sfx("done")
return f"Finished: {target}"
play_sfx("error")
return f"Couldn't find '{text}'"
def delete_task(self, text):
"""Delete a task using fuzzy matching"""
all_tasks = [t["task"] for t in self.tasks]
matches = difflib.get_close_matches(text, all_tasks, n=1, cutoff=0.6)
if matches:
target = matches[0]
self.tasks = [t for t in self.tasks if t["task"] != target]
self.save()
play_sfx("done")
return f"Deleted: {target}"
play_sfx("error")
return f"Couldn't find '{text}' to delete."
def clear_done(self):
"""Remove all completed tasks"""
old_len = len(self.tasks)
self.tasks = [t for t in self.tasks if t["status"] == "pending"]
self.save()
if len(self.tasks) < old_len:
play_sfx("done")
return "Cleared finished tasks!"
else:
return "No finished tasks."
def get_display_list(self):
"""Format tasks for display (pending first, then completed)"""
sorted_tasks = sorted(self.tasks, key=lambda x: x['status'] == 'done')
lines = []
for t in sorted_tasks:
check = "[x]" if t["status"] == "done" else "[ ]"
prio = "(High)" if t['priority'] == "High" else ""
lines.append(f"{check} {t['task']} {prio}")
return "\n".join(lines) if lines else "List is empty."
# ============================================================================
# UI COMPONENTS
# ============================================================================
class GameButton(tk.Button):
"""Custom button with hover effects"""
def __init__(self, master, color, **kw):
super().__init__(master, **kw)
self.color = color
self.config(
bg=color,
fg="#2d4036",
activebackground=THEME["btn_act"],
activeforeground="white",
bd=0,
relief="flat",
cursor="hand2",
font=(THEME["font_retro"], 14, "bold"),
padx=20,
pady=15
)
self.bind("<Enter>", self.on_enter)
self.bind("<Leave>", self.on_leave)
def on_enter(self, e):
"""Brighten button on hover"""
if self['state'] == 'normal':
self['bg'] = "#ffffff"
def on_leave(self, e):
"""Return to original color"""
if self['state'] == 'normal':
self['bg'] = self.color
class RobotFace(tk.Canvas):
"""Animated robot face showing system state"""
def __init__(self, master, size=180):
super().__init__(master, width=size, height=size, bg=THEME["screen"],
bd=0, highlightthickness=0)
self.size = size
self.center = size // 2
self.draw_face("idle")
def draw_face(self, state="idle"):
"""Draw robot face based on current state (idle/listening/processing)"""
self.delete("all")
c = self.center
eye_offset = 35 # Distance from center
eye_size = 12 # Eye radius
# Draw bezel/frame
self.create_rectangle(5, 5, self.size-5, self.size-5,
outline=THEME["face"], width=3)
# Draw eyes based on state
if state == "processing":
# X-shaped eyes for processing
for x_pos in [c-eye_offset, c+eye_offset]:
self.create_line(x_pos-10, c-10, x_pos+10, c+10,
width=4, fill=THEME["face"], capstyle="round")
self.create_line(x_pos-10, c+10, x_pos+10, c-10,
width=4, fill=THEME["face"], capstyle="round")
else:
# Normal circular eyes
self.create_oval(c-eye_offset-eye_size, c-10-eye_size,
c-eye_offset+eye_size, c-10+eye_size,
fill=THEME["face"])
self.create_oval(c+eye_offset-eye_size, c-10-eye_size,
c+eye_offset+eye_size, c-10+eye_size,
fill=THEME["face"])
# Draw mouth based on state
if state == "listening":
# Open "O" mouth when listening
self.create_oval(c-10, c+20, c+10, c+40,
outline=THEME["face"], width=3)
elif state == "processing":
# Flat line mouth when processing
self.create_line(c-15, c+30, c+15, c+30,
fill=THEME["face"], width=3, capstyle="round")
else:
# Smiling arc mouth when idle
self.create_arc(c-20, c+10, c+20, c+40,
start=0, extent=-180, style="arc",
width=3, outline=THEME["face"])
# ============================================================================
# MAIN APPLICATION
# ============================================================================
class VoiceAgentApp:
def __init__(self, root):
self.root = root
self.root.title("To-Do List Agent (LangChain Powered)")
self.root.geometry("1100x850")
self.root.configure(bg=THEME["body"])
self.manager = TaskManager()
self.listening = False
self.audio_queue = []
self.setup_ui()
# Load AI models in background thread to avoid freezing UI
threading.Thread(target=self.load_kernels, daemon=True).start()
def setup_ui(self):
"""Build the user interface"""
body = tk.Frame(self.root, bg=THEME["body"])
body.pack(fill="both", expand=True, padx=40, pady=40)
# === CONTROL BUTTON (Bottom) ===
controls = tk.Frame(body, bg=THEME["body"])
controls.pack(side="bottom", fill="x", pady=(20, 0))
self.btn = GameButton(
controls,
color=THEME["btn_down"],
text="INITIALIZING...",
state="disabled",
command=self.toggle_listen
)
self.btn.pack(fill="x", ipady=10)
# === SCREEN DISPLAY (Top) ===
screen_bezel = tk.Frame(body, bg=THEME["face"], padx=10, pady=10, bd=0)
screen_bezel.pack(side="top", fill="x", pady=(0, 20))
screen = tk.Frame(screen_bezel, bg=THEME["screen"])
screen.pack(fill="both", expand=True)
# Robot face (left side)
self.face = RobotFace(screen, size=160)
self.face.pack(side="left", padx=20, pady=20)
# Logs (right side)
logs = tk.Frame(screen, bg=THEME["screen"])
logs.pack(side="right", fill="both", expand=True, padx=20, pady=20)
# Transcription display
self.trans_box = tk.Text(
logs, height=4, bg=THEME["screen"], fg=THEME["face"],
bd=0, font=(THEME["font_retro"], 14), state="disabled"
)
self.trans_box.pack(fill="x")
# Separator line
tk.Frame(logs, height=2, bg=THEME["face"]).pack(fill="x", pady=10)
# Log messages display
self.log_box = tk.Text(
logs, height=4, bg=THEME["screen"], fg=THEME["face"],
bd=0, font=(THEME["font_mono"], 11), state="disabled"
)
self.log_box.pack(fill="x")
# === TASK LIST (Middle) ===
task_frame = tk.Frame(body, bg="#4da896", bd=0, padx=5, pady=5)
task_frame.pack(side="top", fill="both", expand=True)
tk.Label(
task_frame, text=" MY LIST ", bg="#4da896", fg="white",
font=(THEME["font_retro"], 10, "bold")
).pack(anchor="w")
self.todo_box = tk.Text(
task_frame, bg="#4da896", fg="white", bd=0,
font=(THEME["font_mono"], 14), spacing1=5,
state="disabled", height=1
)
self.todo_box.pack(fill="both", expand=True, padx=10, pady=5)
def write_to_widget(self, widget, text, clear_first=False):
"""Helper function to write to read-only text widgets"""
widget.config(state="normal")
if clear_first:
widget.delete("1.0", "end")
widget.insert("end", text)
widget.see("end")
widget.config(state="disabled")
def load_kernels(self):
"""Load AI models"""
try:
print("1. Loading Draft Ear (Tiny) - FAST...")
self.draft_ear = WhisperModel("tiny.en", device="cpu", compute_type="int8")
print("2. Loading Main Ear (Small) - ACCURATE...")
self.ear = WhisperModel("small.en", device="cpu", compute_type="int8")
print("3. Loading Brain (LangChain Chain)...")
# UPDATED: Use the helper function from agent_logic.py
self.chain = initialize_chain(MAIN_MODEL_PATH)
# Enable UI once models are loaded
self.root.after(0, lambda: self.btn.config(
text="START LISTENING", state="normal", bg=THEME["btn_up"]
))
self.root.after(0, lambda: self.write_to_widget(
self.trans_box,
"System Online (LangChain).\nReady.",
clear_first=True
))
self.refresh_todo_list()
except Exception as e:
print(f"ERROR loading models: {e}")
def toggle_listen(self):
"""Start/stop voice listening"""
if not self.listening:
self.listening = True
self.btn.config(text="STOP LISTENING", bg=THEME["btn_down"])
self.face.draw_face("listening")
threading.Thread(target=self.record_loop, daemon=True).start()
else:
self.listening = False
self.btn.config(text="START LISTENING", bg=THEME["btn_up"])
self.face.draw_face("idle")
def record_loop(self):
"""Continuously record audio and detect voice activity"""
def callback(indata, frames, time, status):
if self.listening:
self.audio_queue.append(indata.copy())
silence_chunks = 0
voice_active = False
with sd.InputStream(samplerate=16000, channels=1,
callback=callback, device=1):
while self.listening:
time.sleep(0.1)
if len(self.audio_queue) == 0:
continue
recent_data = np.concatenate(self.audio_queue[-3:])
volume = np.linalg.norm(recent_data) * 10
if volume > 2.0:
silence_chunks = 0
voice_active = True
self.root.after(0, lambda: self.face.draw_face("listening"))
else:
silence_chunks += 1
if voice_active and silence_chunks > 16:
self.root.after(0, lambda: self.face.draw_face("processing"))
full = np.concatenate(self.audio_queue)
self.audio_queue = []
silence_chunks, voice_active = 0, False
self.process_audio(full.flatten())
def process_audio(self, audio):
"""Process audio with speculative decoding + LangChain Task Classification"""
try:
# Normalize audio
max_val = np.max(np.abs(audio))
if max_val > 0:
audio = audio / max_val * 0.8
# --- Speculative Decoding (Whisper) ---
print("[DRAFT] Transcribing with tiny.en...")
draft_segments, _ = self.draft_ear.transcribe(
audio, beam_size=1, language="en", condition_on_previous_text=False
)
draft_text = " ".join([s.text for s in draft_segments]).strip()
if len(draft_text) > 5:
print("[VERIFY] Verifying with small.en...")
segments, _ = self.ear.transcribe(
audio, beam_size=5, language="en", condition_on_previous_text=False,
vad_filter=True, vad_parameters=dict(min_silence_duration_ms=400)
)
text = " ".join([s.text for s in segments]).strip()
else:
text = draft_text
if len(text) < 3 or text.lower() in ["you", "thank you.", "oh my god."]:
return
self.root.after(0, lambda: self.write_to_widget(
self.trans_box, f'"{text}"', clear_first=True
))
# --- LANGCHAIN LOGIC START ---
current_tasks = [t["task"] for t in self.manager.tasks]
try:
# UPDATED: Replaces the manual Prompt + Parsing Logic
action_data = run_agent(self.chain, text, current_tasks)
# Execute Logic
action = action_data.get("action")
result_msg = ""
if action == "add":
result_msg = self.manager.add_task(
action_data.get("task", "Unknown"),
action_data.get("priority", "Medium")
)
elif action == "complete":
result_msg = self.manager.mark_done(
action_data.get("target", "")
)
elif action == "delete":
result_msg = self.manager.delete_task(
action_data.get("target", "")
)
elif action == "clear_done":
result_msg = self.manager.clear_done()
# Display result
self.root.after(0, lambda: self.write_to_widget(
self.log_box, result_msg, clear_first=True
))
self.root.after(0, self.refresh_todo_list)
except Exception as e:
print(f"LangChain Execution Error: {e}")
except Exception as e:
print(f"Error processing audio: {e}")
self.audio_queue = []
def refresh_todo_list(self):
"""Update the task list display"""
display_text = self.manager.get_display_list()
self.write_to_widget(self.todo_box, display_text, clear_first=True)
if __name__ == "__main__":
root = tk.Tk()
app = VoiceAgentApp(root)
root.mainloop()
Tech Stack
- > Algorithm: Speculative Inference (ASR Layer)
- > Frameworks: LangChain (LCEL), Faster-Whisper
- > Models: Whisper (Tiny/Small) + Phi-3 Mini (GGUF)
- > Hardware: NVIDIA RTX 4060